
Análisis del acuerdo entre codificadores
Análisis del acuerdo entre codificadores
Estoy trabajando en un equipo. Sería fantástico si pudiéramos analizar la concordancia entre codificadores de nuestro trabajo. ¿Es esto posible con ATLAS.ti?
En ATLAS.ti 8 y posteriores, puede probar la concordancia entre codificadores en documentos de texto, audio y vídeo. Los documentos de imagen no están soportados.
La herramienta de concordancia entre codificadores de ATLAS.ti le permite evaluar la concordancia de cómo múltiples codificadores codifican un cuerpo de datos dado. En el desarrollo de la herramienta hemos trabajado estrechamente con el profesor Klaus Krippendorff , uno de los principales expertos en este campo, autor del libro Content Analysis: An Introduction of Its Methodology, y creador del coeficiente alfa de Krippendorff.
Además del alfa de Krippendorff, puede utilizar el porcentaje de acuerdo o el índice de Holsti para medir el acuerdo entre codificadores.
Obtenga más información sobre cómo aplicarlo en nuestros "Documentos sobre cómo hacerlo".
Acuerdo porcentual
El porcentaje de acuerdo es la medida más sencilla de acuerdo entre codificadores. Se calcula como el número de veces que un conjunto de valoraciones es igual, dividido por el número total de unidades de observación que se valoran, multiplicado por 100.
Las ventajas del porcentaje de acuerdo son que es sencillo de calcular y que puede utilizarse con cualquier tipo de escala de medición.
Así es como se calcula
Porcentaje de acuerdo (PA) = número de acuerdos / número total de segmentos
Índice de Holsti
El índice de Holsti es una variación de la medida de acuerdo porcentual para situaciones en las que los codificadores no codifican precisamente el mismo segmento de datos. Este es el caso si los codificadores establecen el suyo propio. Al igual que el porcentaje de acuerdo, el índice de Holsti tampoco tiene en cuenta el acuerdo fortuito.
La fórmula del índice de Holsti es
PA (Holsti) = 2A/ (N1+N2)
PA (Holsti) representa el porcentaje de acuerdo entre dos codificadores; A es el número de decisiones consensuadas de los dos codificadores, y N1 y N2 son los números de decisiones que los codificadores han tomado respectivamente .
Los resultados del porcentaje de acuerdo y del índice Holsti son los mismos cuando todos los codificadores codifican los mismos segmentos de datos.
Familia de coeficientes alfa de Krippendorff
La familia de coeficientes alfa ofrece varias medidas que permiten realizar cálculos a diferentes niveles. Pueden utilizarse para más de dos codificadores, son sensibles a diferentes tamaños de muestra y pueden utilizarse también con muestras pequeñas.
Familia de coeficientes alfa de Krippendorff: de lo general a lo específico
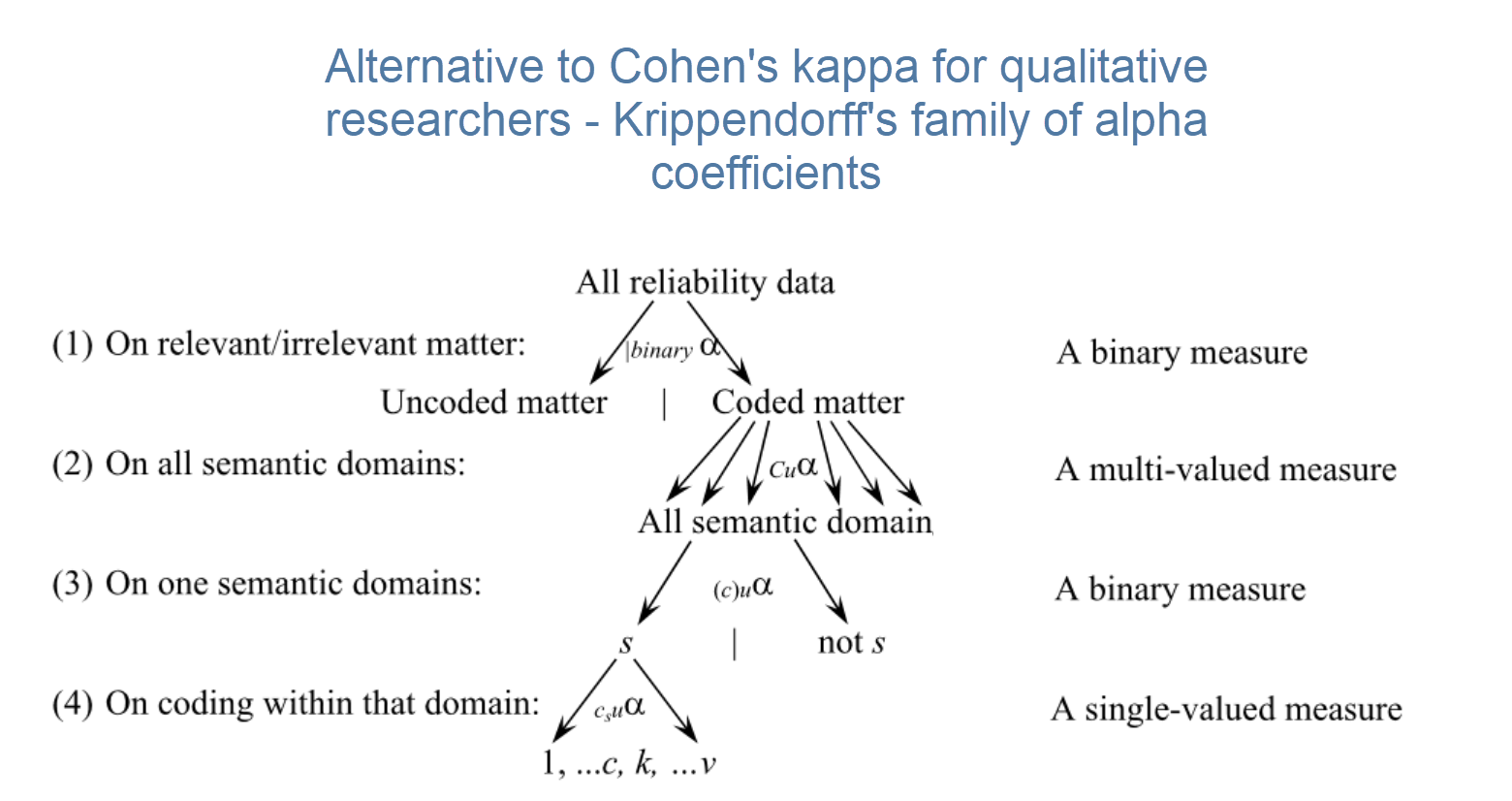
Alfa binario
En el nivel más general, se puede medir si diferentes codificadores identifican las mismas secciones en los datos como relevantes para los temas de interés representados por los códigos. Para este análisis se tienen en cuenta todas las unidades de texto, tanto los datos codificados como los no codificados.
Se puede, pero no es necesario, utilizar dominios semánticos a este nivel. También es posible introducir un único código por dominio. Se obtiene un valor de alfa binario para cada código (o cada dominio semántico) en el análisis, y un valor global para todos los códigos (o todos los dominios) en el análisis.
El valor global de alfa binario puede ser algo que se quiera publicar en un artículo como valor global de acuerdo entre codificadores para su proyecto.
Los valores de cada código o dominio semántico proporcionan información sobre qué códigos o dominios son satisfactorios en términos de acuerdo entre codificadores y cuáles son entendidos de forma diferente por los distintos codificadores. Se trata de códigos/dominios que hay que mejorar y probar, aunque sea con diferentes codificadores.
Consejo: Si trabaja con citas predefinidas, el coeficiente binario será 1 para un dominio semántico si sólo se han aplicado códigos del mismo dominio semántico, independientemente de qué código dentro del dominio se haya aplicado.
El valor del binario alfa global siempre será 1 cuando se trabaje con citas predefinidas ya que todos los segmentos codificados son iguales.
cu-alfa
Otra opción es comprobar si diferentes codificadores fueron capaces de distinguir entre los códigos de un dominio semántico. Por ejemplo, si tiene un dominio semántico llamado EMOCIONES con los subcódigos:

El coeficiente le indica si los codificadores fueron capaces de distinguir de forma fiable entre, por ejemplo, "alegría" y "excitación", o entre "miedo" y "enfado". El coeficiente le dará un valor para el rendimiento general del dominio semántico. Sin embargo, no le dirá cuál de los subcódigos puede ser problemático. Hay que mirar las citas y comprobar dónde está la confusión.Cu-alfa
Cu-alfa es el coeficiente global para todas las cu-alfas. Tiene en cuenta que se pueden aplicar códigos de múltiples dominios semánticos a las mismas citas o a las que se solapan. Por lo tanto, Cu-alfa no es sólo la media de todos los cu-alfas.
Si se han aplicado códigos de un dominio semántico "A" a segmentos de datos que están codificados con códigos de un dominio semántico "B", esto no afecta al coeficiente cu-alfa ni del dominio A ni del B, pero sí al coeficiente Cu-alfa global.
Se puede interpretar el coeficiente Cu-alfa como un indicador del grado de acuerdo de los codificadores sobre la presencia o ausencia de los dominios semánticos en el análisis. Formulado como una pregunta: ¿Pueden los codificadores identificar con fiabilidad que los segmentos de datos pertenecen a un dominio semántico específico, o los distintos codificadores aplicaron códigos de otros dominios semánticos?
En el cálculo del coeficiente cu- y Cu-alfa, sólo se incluyen en el análisis los segmentos de datos codificados.
csu-alfa
Este coeficiente también pertenece a la familia de los coeficientes alfa, pero aún no está implementado. Una vez implementado, permitirá profundizar un nivel más, y se podrá comprobar para cada dominio semántico qué código dentro del dominio funciona bien o no tan bien. Indica la concordancia en la codificación dentro de un dominio semántico.
Kappa de Cohen
Reconocemos que el Kappa de Cohen es una medida popular, pero hemos optado por no aplicarla porque sólo puede utilizarse para 2 codificadores, supone un tamaño de muestra infinito, lo que nunca es el caso en la investigación cualitativa, y debido a las conocidas limitaciones identificadas en la literatura:
"Es bastante desconcertante por qué la kappa de Cohen ha sido tan popular a pesar de la gran controversia que existe con ella. Los investigadores empezaron a plantear problemas con la kappa de Cohen hace más de tres décadas (Kraemer, 1979; Brennan y Prediger, 1981; Maclure y Willett, 1987; Zwick, 1988; Feinstein y Cicchetti, 1990; Cicchetti y Feinstein, 1990; Byrt, Bishop y Carlin, 1993). En una serie de dos artículos, Feinstein & Cicchetti (1990) y Cicchetti & Feinstein (1990) dieron a conocer las siguientes dos paradojas con el kappa de Cohen (1) Un kappa bajo puede ocurrir con un acuerdo alto; y (2) Las distribuciones marginales desequilibradas producen valores más altos de kappa que las distribuciones marginales más equilibradas. Aunque las dos paradojas no se mencionan en los libros de texto más antiguos (por ejemplo, Agresti, 2002), se introducen completamente como las limitaciones de kappa en un libro de texto reciente para graduados (Oleckno, 2008). Además de las dos conocidas paradojas mencionadas, Zhao (2011) describe doce paradojas adicionales con kappa y sugiere que la kappa de Cohen no es en absoluto una medida general para la fiabilidad entre evaluadores, sino una medida de fiabilidad en condiciones especiales que raramente se dan.
Krippendorff (2004) sugiere que el kappa de Cohen no está calificado como una medida de fiabilidad en el análisis de fiabilidad ya que su definición de acuerdo de azar se deriva de las medidas de asociación debido a su suposición de la independencia de los calificadores. Sostiene que en el análisis de fiabilidad los calificadores deberían ser intercambiables y no independientes, y que la definición de acuerdo de azar debería derivarse de las proporciones estimadas como aproximaciones a las proporciones reales en la población de datos de fiabilidad. Krippendorff (2004) demuestra matemáticamente que el desacuerdo esperado de kappa no es una función de las proporciones estimadas de los datos de la muestra, sino una función de las preferencias individuales de dos calificadores para las dos categorías." (Xie, 2013).